.jpg)
Pyrhon(パイソン)のデータ分析で前処理と可視化ってどうするの?
データ分析初心者の登竜門、「タイタニックの生存者予測」。
Kaggle(カグル)という世界中の機械学習・データサイエンスに携わっている約40万人の方が集まるコミニティーで初心者向けにチュートリアルとして公開されている有名なデータセットです。
これらのデータセットを使って「分類器」を作成し、タイタニックの乗客の生存の是非を予測します。
このTitanicデータセットはPythonは何となく使えるようになったけど、とりあえず機械学習をやってみたい!という方にオススメです。
データ分析をする上で、下記流れで行います。
- データを取り込む
- データを整理する
- データを分類する
- 結果を検証する
今回はタイタニックのデータを使ってデータの前処理として、データの取り込みとデータ整理してみました!
以下、Jupyter notebookを使って実際にPythonのコードを書いていきます。
まだPythonの環境を構築していない方はこちらの記事をお読みください。
関連記事Python(パイソン)環境をAnaconda(アナコンダ)で構築!Jupyter notebookの使い方は?
Pythonでタイタニックのデータ分析する事前準備
Titanic: Machine Learning from Disaster
Pythonでタイタニックのデータ分析する前に準備が必要です。
データをダウンロードして読み込んでみよう!
まずは、kaggleのサイトにアクセスします。
関連サイトタイタニックデータセット
kaggleを利用するには会員登録する必要があるので、サイト右上の「Register」ボタンをクリックします。
無料で登録出来ます♪
Googleのアカウントで簡単に登録できます。
登録してサインインしたら、タイタニックデータセットをこちらからダウンロードします。
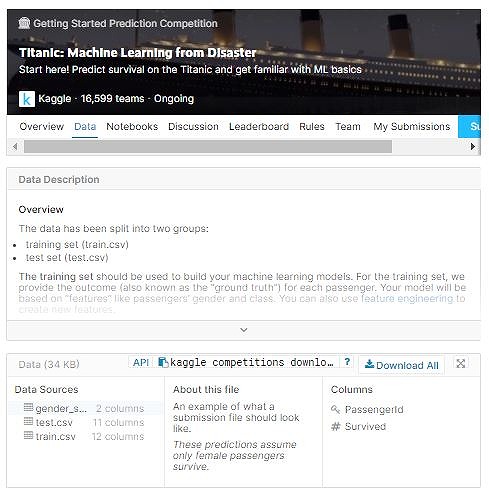
Dataの【Downoad all】からデータをダウンロードすることが出来ます。
titanic.zipというファイルがダウンロードされたら、Jupyter notebookで作業するフォルダで解凍します。
Windows端末だと、デフォルトでは、【Windows(c)>ユーザー>ユーザー名】の直下がJupyter notebookの作業場になっているかと思います。
- test.csv(27.96 KB)
- train.csv (59.76 KB)
NumpyとPandasを使ってダウロードした上記のデータセット、「test.csv」と「train.csv」を読み込みます。
#ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline#データセットの読み込み
train = pd.read_csv("./titanic/train.csv",index_col=0)
test = pd.read_csv("./titanic/test.csv",index_col=0)Pandasライブラリで、index_col=0のように使いたい列の列番号を0始まりで指定します。
データの中身を確認してみよう!
さっそく、データの中身を確認してみましょう!
各列の要素(カラム)を確認します。
カラム確認には、.columns関数を使います。
#各列の要素を確認
train.columnsトレーニングデータの要素は下記の11。
Index([‘Survived’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Ticket’, ‘Fare’, ‘Cabin’, ‘Embarked’], dtype=’object’)
#各列の要素を確認
test.columnsトレーニングデータの要素は下記の10。
Index([‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’, ‘Parch’, ‘Ticket’, ‘Fare’,
‘Cabin’, ‘Embarked’],
dtype=’object’)

テストデータには、’Survived’という要素がないことが分かります。
配列を確認するには、.shape関数を使います。
#データの配列の大きさを確認
train.shape#データの配列の大きさを確認
test.shape
- ‘Survived’:生存の是非。1は生存、0は死亡
- ‘Pclass’:客室の等級。1が最高級
- ‘Name’:氏名(敬称付き)
- ‘Sex’:性別
- ‘Age’:年齢
- ‘SibSp’:乗船した兄弟の数
- ‘Parch’:乗船した親・子の数
- ‘Ticket’:チケット番号
- ‘Fare’:乗船代金
- ‘Cabin’:部屋番号
- ‘Embarked’:乗船した港。S,C,Qの3種類
データの欠損値を確認してみよう!
データセットは必ずしも「完全なもの」であるとは限りません。
つまり、そのままではデータ分析出来ない(場合もある)んです。
取得データのうち、ある項目の値が欠けているものを欠損値と言います。
欠損値の有無は必ず確認するのが大事。
欠損値(missing value)とは:アンケート調査データの場合の無回答項目やカルテデータの場合の未検査項目のように,あるケースのある項目の値が欠落している場合がある。ほとんどの統計プログラムパッケージでは,1ケースあたりの変数の個数は等しくなければならないので,データファイルを準備する場合には,データが欠落している場合でもなんらかの数値を入力しておかなければならない。ただし,入力される数値は実際にはデータがなかったことを表しているので,分析対象からはずす必要がある。そのため,他の有効なデータと明らかに区別できる値(欠損値)を入力する。例えば,正の値しか取らない変数には欠損値として負の値を与える。あるいは,通常では出現しないような大きな値を与えるなどが適当であろう。
欠損要素をTrue、それ以外をFalseに変換するには、.isnull()関数を使います。
train.isnull()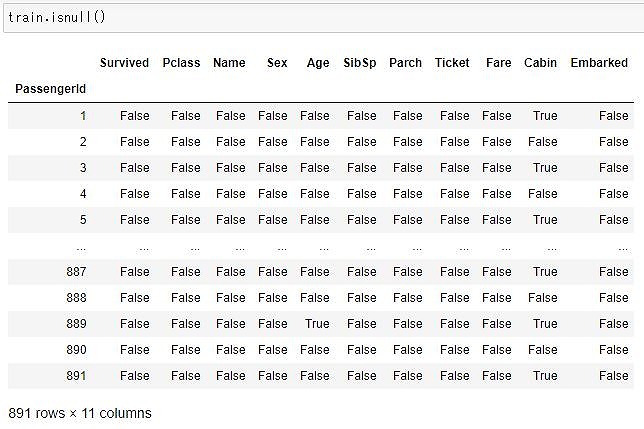
各列の欠損値の数をカウントするにはisnull().sum()関数。
train.isnull().sum()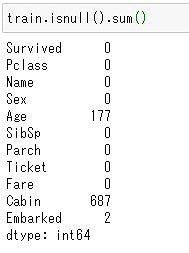
各列の欠損値ではない要素数をカウントするにはnotnull().sum()関数。
train.notnull().sum()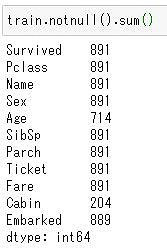
これにより、トレーニングデータには「Age」、「Cabin」、「Embarked」に欠損値があることが分かりましたね。
ここで、データ分析する場合の疑問です。
 ヨシタカ
ヨシタカ欠損しているデータは補完した方がいいの?それとも削除した方がいいの?
欠損値の補完(何かしらのデータで埋めてしまう)はデータ数を減らさずに済みますが、「真のデータ分布」から外れるリスクがあります。
補完するよりも削除してしまった方が良い場合もあるんだとか。
今回は削除してみましょうか!
データの欠損値を削除してみよう!
ここでは、データの欠損値を削除します。
テストデータの欠損値も確認します。
test.isnull().sum()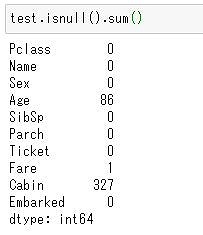
テストデータには「Age」、「Fare」、「Cabin」に欠損値があることが分かりましたね。
train.csv、test.csvの「Age」、「Fare」、「Cabin」、「Embarked」のデータを削除してみます。
削除は.drop()関数を使います。
.drop()関数では、引数labelsとaxisで指定します。行の場合はaxis=0、列の場合はaxis=1となります。
今回は列を削除したいのでaxis=1です。
drop_columns = ["Age","Cabin","Fare","Embarked"]
train_modify = train.drop(drop_columns,axis=1)
test_modify = test.drop(drop_columns,axis=1)train_modify.isnull().sum()、test_modify.isnull().sum()で確認します。
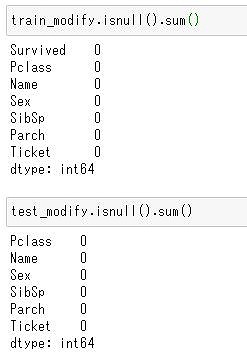
ちゃんと削除されてますね。
データを可視化してみよう!
今回のお題は、「タイタニックの生存者予測」。
【Survived】が重要になります。
ってことで。
このデータセットでは、生存が「1」、死亡が「0」なので平均を求めれば、生存率が算出出来ます。
ここで、.mean()関数を使います。
train.Survived.mean()上記で生存率を求めてみると、38.4%と求まりました。
ざっくりですが、トレーニングデータから1/3の方が生存したことが分かります。
生き残った人・亡くなった人の割合は?
生き残った人・亡くなった人の割合は下記で調べることが出来ます。
円グラフで表示してみませう。
円グラフはplt.pie関数を使います。
plt.pie(train["Survived"].value_counts(),labels=["Deceased","Survived"],autopct="%.1f%%")
plt.title("Ratio of the Survived/Deceased")
plt.show()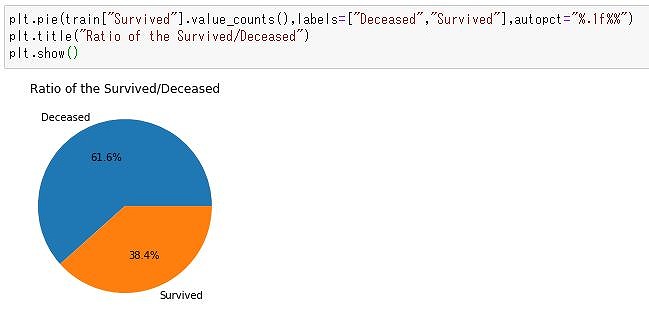
男女別の生存数は?
次は、男女それぞれの生存者数を見てみます。
.groupby()関数でグループ分けをして、.sum()関数を使うことで、生存者数を求めることが出来ます。
ここでは、性別”Sex”の項目でグループ分けして、生存者数の合計を求めてみます。
train.groupby(["Sex"]).sum()["Survived"]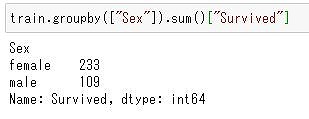
棒グラフにしてみると・・・
train.groupby(["Sex"]).sum()["Survived"].plot.bar(color=['mistyrose', 'lightblue'])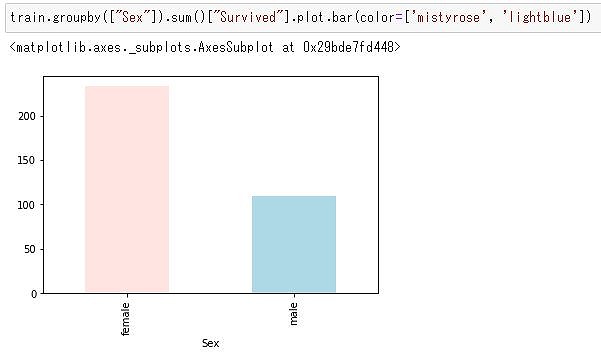
男女別の生存者数・死者数は?
次は男女それぞれの生存者数・死者数を見てみます。
train.groupby(["Sex","Survived"])["Survived"].count()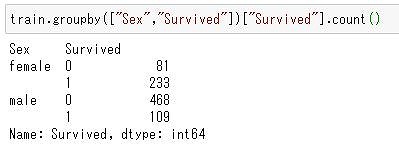
これをグラフにしてみると下記のようになります。
train.groupby(["Sex","Survived"])["Survived"].count().plot.bar(color=["mistyrose","lightcoral","lightblue","deepskyblue"])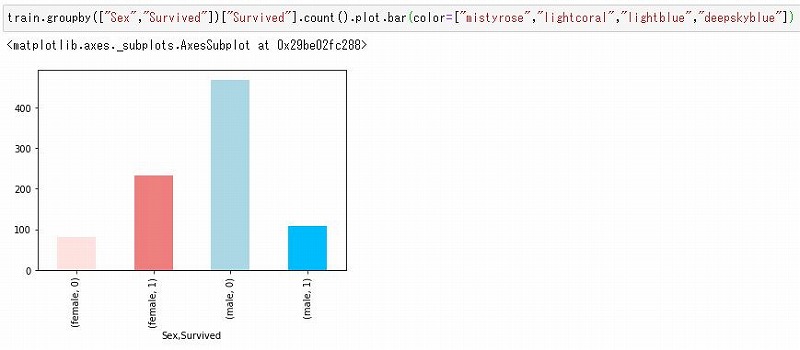
男女別の生存率は?
男女別の生存率を調べてみます。
.mean()関数で生存率が分かります。
train.groupby(["Sex"]).mean()["Survived"]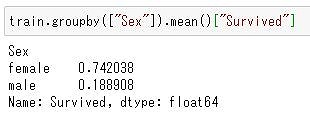
train.groupby(["Sex"]).mean()["Survived"].plot.bar(color=["lightcoral","deepskyblue"])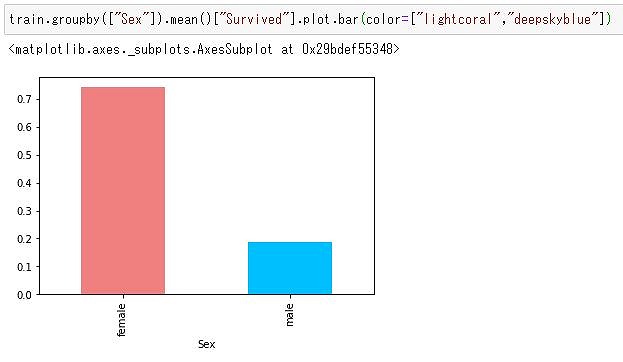
トレーニングデータの「性別」に着目すると、女性の方が明らかに生存率が高いことが分かりますね。
どうやら性別は生存率に寄与しそうだぞ!?と機械学習しなくてもなーんとなく分かります。
データを可視化してみるとイメージが湧きますよね。
さあPythonでタイタニックデータ分析してみよう!
PythonでKaggleのタイタニックデータセットでデータの前処理をしてみました。
データ分析には前準備が非常に重要になります。
どのデータをどう扱うのか。
今回は欠損値を探して、削除してみました。
削除した方がいい場合もありますし、データを補完した方が良い場合もあります。
色々と試してみてくださいね。
次回はデータの加工(特徴構築)をしてみたいと思います。
-300x199.jpg)
コメント